
This blog is to describe how to configure the Segger Embedded Studio to support the UTF8 coding inside its IDE.
What is UTF-8?
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.
UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more frequently, are encoded using fewer bytes. It was designed for backward compatibility with ASCII: the first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single byte with the same binary value as ASCII, so that valid ASCII text is valid UTF-8-encoded Unicode as well. Since ASCII bytes do not occur when encoding non-ASCII code points into UTF-8, UTF-8 is safe to use within most programming and document languages that interpret certain ASCII characters in a special way, such as “/” (slash) in filenames, “\” (backslash) in escape sequences, and “%” in printf.
For example on the Chinese Coding,
Althought in English it is sufficient to encode a character in ASCII code with a single byte, in some languages like Chinese, a character may require multiple bytes. There were some popular encodings for Chinese characters, such as Big5 for traditional Chinese characters in Taiwan, and GB2312 for simplified Chinese characters in Mainland China. Both the abovementioned encodings require two bytes to represent a Chinese character.
However, there are totally more than 65536 Chinese character, although only a few thousands are in common use. If we limit ourselves in two-byte encoding, this implies that some Chinese characters cannot be corrected represented. This will force us to give up some characters, which is a terrible idea especially when the character is among the name of a person.
Therefore, to encoding all possible Chinese characters, you will need more bytes. UTF-8 is an encoding which represents a Chinese character with 3 bytes. For example, the Chinese character ‘中’ is represented by 3 hexadecimal bytes as “\xe4\xb8\xad”, while the Chinese character ‘文’ is represented by “\xe6\x96\x87”.
You may define strings consisting of Chinese characters as
string msg1 = "中文";
char msg2[] = "\xe4\xb8\xad\xe6\x96\x87";
How to configure the KEIL on the UTF-8
Select the icon of the tool
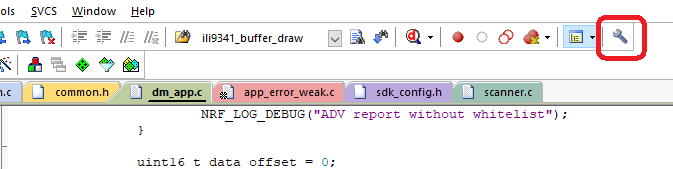
And then select the encode in UTF-8 without signature

How to configure the Segger Embedded Studio to support the UTF-8 coding
Tools -> options -> Text Editors

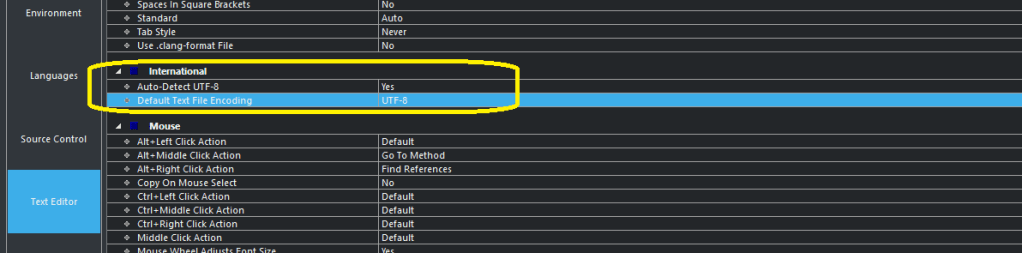
For the display of the font, it needs to configure (Text Editor -> Visual Appearance –> Font Rendering –> Proportional

